The Anatomy of Listening: Designing Audio AI That Understands Context

The next frontier of Audio AI lies not in capturing clearer speech but in achieving deeper comprehension. According to recent market research, the global Audio AI recognition market is projected to exceed US$19.63 billion by 2033, underscoring a market's shift toward models that comprehend meaning rather than just process sound.
Imagine asking a voice assistant, "Can you open the aircon?" and it hears, "I can't find Eric on." Or saying, "Book a grab to Orchard," and the system transcribes, "Buy a crab in Orchard." These aren't simply transcription errors. They expose how many current voice models still struggle to understand the speech patterns common across Southeast Asia.
In Southeast Asia, "open the aircon" or "close the light" are perfectly natural expressions, yet when models trained on Standardized American or British English treat them as mistakes. To advance beyond transcription, Audio AI must learn to interpret regional rhythm, phrasing, and code-mixed speech patterns common in Singapore, Malaysia, and the Philippines.
This piece explores how embracing accent diversity, modeling ambiguity, and leveraging expert human feedback can pivot AI from hearing to comprehension.
The Accent Problem in Speech AI
The core issue of Audio AI isn't poor transcription; it's the inability to listen. Automated speech recognition (ASR) models are built to detect words with high accuracy, not to understand meaning. They match sounds to text rather than interpret how people actually speak.
Most models are optimized for standardized English, learning only a narrow range of pitch, pacing, and pronunciation. When confronted with regional or multilingual accents, they lose rhythm, distort tone, and strip away nuance.
For many users, that gap translates into exclusion. Voice assistants and transcription platforms don't just misinterpret; they actively discriminate.
Performance & Systemic Bias
These design flaws translate directly into measurable inequities. ASR models perform up to twice as poorly with non-native or regional accents compared to Standard American or British English, which still dominate most training data. This imbalance reflects how current models equate "accuracy" with familiarity. They perform best only on the voices they were trained to hear.
A 2022 global study across 2,700 English-speaking voices from 171 countries found that speech models from Amazon, Google, and Microsoft consistently produced higher error rates for non-native speakers. Similarly, a Stanford analysis exposed the same critical flaw: near-perfect accuracy for U.S. English but a 35% Word Error Rate (WER) for dialectal English—almost double the 19% average for white speakers.
The discrepancies stem from acoustic-model bias, where models trained on narrow phonetic and rhythmic patterns fail to generalize across global voices.
Asia's Missing Voices
Those disparities aren't abstract; they shape daily interactions in some of the world's fastest-growing voice markets. Nowhere is this clearer than in Asia, where multilingual speakers mix English with Malay, Chinese, Tamil, Tagalog, and other local languages. Most open datasets underrepresent these voices, making models unable to capture local rhythm and phrasing.
- Air-traffic-control studies highlight the difference. Western-trained ASR had error rates exceeding 90% for Southeast Asian-accented English, dropping to 9.82% after retraining with local data.
- In South Asia, accent-aware retraining of DeepSpeech2 cut misinterpretation from 43% to 18.08% (including Indian, Pakistani, and Bangladeshi speakers).
- Fine-tuning for code-mixed speech, such as English and Malay, achieved a 100% relative improvement in WER.
Voice AI only becomes equitable when it learns from the people it's meant to serve. The next step isn't building systems that hear better, but designing ones that listen more deeply to intent, emotion, and culture.
How Audio AI Can Learn to Understand Intent
Human communication is far richer than a clean audio signal. It's full of ambiguity, emotion, and subjective context that machines fail to decode. True comprehension means teaching AI to navigate this subjective layer.
Accent, Ambiguity, and Emotion
Regional accents influence pronunciation, intonation, and rhythm, traits linguists call prosodic features. Ambiguity compounds the problem: background noise, overlapping voices, or poor recordings can corrupt the signal. For instance, a calm "I'm fine" sounds reassuring, while a tense "I'm fine" signals distress. Yet, to most models, both instances are identical transcripts.
The Human-in-the-Loop Solution: Calibration
Machines learn to interpret tone, rhythm, and nuance only when guided by human annotation. Annotators act as the "ears" of AI models, labeling tone, emotion, and intent where raw data falls short.
- Annotation as Understanding: Annotators shift the focus from simple transcription accuracy to measuring understanding of intent.
- Modeling Emotion and Subjectivity: Emotion labeling combines categorical labels (e.g., anger, joy, sadness) with dimensional models that measure valence (positive to negative), arousal (calm to excited), and dominance (passive to active). This hybrid approach helps systems interpret emotion as a continuous spectrum.
- Building Shared Judgment: Annotators align their interpretations through exposure-based training and shared "gold clips." Including annotators from multiple linguistic regions ensures AI learns diverse listening patterns reflective of real-world voices.
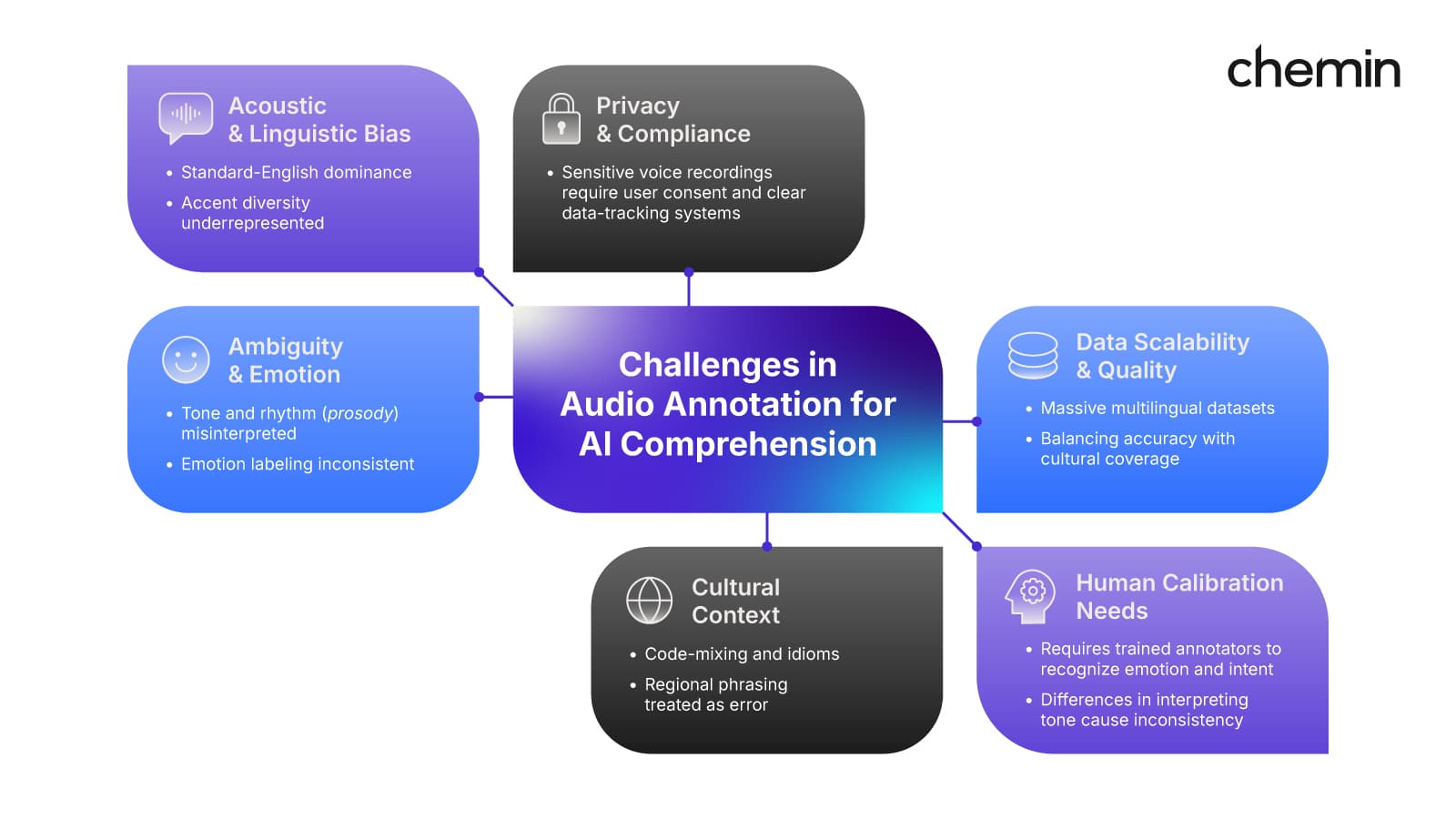
Figure 1. The many layers of complexity in audio annotation.
From accent bias to emotional ambiguity, effective Audio AI requires human calibration to navigate context, culture, and subjectivity.
From Technical Augmentation to Enterprise Intelligence
Human feedback teaches AI to understand nuance, but engineering ensures that this intelligence holds up across every voice and setting.
Augmentation and Adaptation
The first step is reducing acoustic-model bias by training models to cope with the unpredictability of real-world speech. These methods strengthen accuracy, speed deployment, and improve scalability in multilingual markets.
- Data Augmentation: Varying pitch, speed, and background noise exposes models to acoustic variation, helping them generalize across accents and recording conditions.
- Accent-aware Training and Transfer Learning: Retraining or fine-tuning existing models on region-specific datasets improves performance without starting from scratch. This approach particularly benefits Southeast Asian markets, where code-switching between languages is common.
- Contextual and Multimodal Enhancement: Advanced systems combine voice with biosignals to map affective states such as valence and arousal, strengthening comprehension of subtle meaning.
- Operational Intelligence: Audio AI converts ambient non-speech sounds into actionable data, providing predictive insights into equipment or process flaws.
The Human Touch: Business Impact
Even the most advanced models still rely on human feedback to accurately interpret meaning. Humans provide contextual judgment, empathy, and cultural awareness. Keeping humans in the loop is essential for establishing enterprise value and user trust.
- Customer experience: Emotion-aware voice assistants enhance user trust and engagement, with Gartner reporting that AI-driven emotion recognition can raise customer satisfaction by up to 50%.
- Compliance and Risk: Recognizing speaker identity, language variety, and emotion reduces error in regulated settings.
- Leading Adopters: Companies such as BMW, DHL, and Unilever exemplify how human validation strengthens machine precision in large-scale deployment.
- At BMW's Dingolfing plant, AI-based acoustic inspection automates final quality checks by analyzing cabin sounds for irregularities.
- DHL's use of Honeywell's Lydia Voice system achieves 99% speech-command accuracy and boosts worker productivity by 35%, cutting manual input errors in half.
- Unilever equips its logistics fleet with Joctan AI, which detects distracted or fatigued driving behaviors through facial and acoustic cues, triggering real-time in-cabin alerts that enhance driver awareness and safety.
Together, these use cases show that audio-driven AI systems, guided by human oversight, prove that sound judgment still requires human ears.
Building AI That Knows How To Listen
Audio AI goes beyond speech recognition; it shapes how organizations interpret customers, employees, and markets.
AI models fundamentally inherit the cultural and linguistic biases of their data. When ASR systems fail to recognize diverse accents or decode emotional intent, they introduce equity risks that undermine trust and business performance. These failures weaken performance and represent a structural challenge in a market projected to exceed US$19.63 billion by 2033.
Spotify built loyalty by turning billions of listening patterns into experiences that reflect each user's context. The same principle applies to enterprises adopting Audio AI: comprehension drives trust, engagement, and operational precision.
By investing in diverse voice data, human-guided calibration, and adaptive modeling, enterprises pioneer AI models that move beyond accuracy to genuine understanding.
Chemin partners with enterprises to transform audio into strategic intelligence—integrating regional datasets, expert annotation, and scalable engineering to build AI that listens deeply and acts with precision.
AI that listens well performs better. If your organization is ready to build with linguistic depth and cultural intelligence, connect with us or visit our website.
Discover more
Global vs Local: Testing GPT-4o-mini and SEA-LIONv3 on Bahasa Indonesia
We tested two Large Language Models (LLMs), GPT-4o-mini and SEA-LIONv3, on their handling of Indonesian-specific questions.
Chemin's Bilingual Dataset for Evaluating Reasoning Skills in STEM Subjects
Fresh out of the oven! Our team just released a bilingual multimodal dataset for evaluating reasoning skills in STEM Subjects.

Press Release: TDCX and SUPA tie-up to help companies address a key barrier in generative AI adoption
Collaboration provides companies with a one-stop-solution for their data labeling needs.