Championing STEM progress through linguistic accessibility
500
Math and Physics questions
Public
leaderboard with results
HuggingFace
open resource benchmark
USE CASE
Dataset Curation
INDUSTRY
STEM
SOLUTION
Data Stack
The mission: Advance multilingual and multimodal benchmarks for AI in STEM
We aimed to create a bilingual STEM dataset in Malay and English, based on real exam questions and paired with visuals, to test AI reasoning across languages and modalities.
The challenge: Lack of datasets to support STEM-related model training
AI in STEM brims with potential, but models struggle with bilingual and multimodal STEM tasks due to the scarcity of high-quality, domain-specific datasets in both Malay and English.
Key obstacles
- No prior datasets to benchmark complex STEM reasoning tasks
- Difficulty in selecting suitable STEM subjects to work on from the multiple domains
The goal
Build a reliable evaluation set for AI teams to fine-tune or assess model reasoning in STEM while improving accessibility for underrepresented languages.
The solution: A bilingual, reasoning-focused STEM dataset
We curated a dataset to support multilingual learners by embedding accessibility, real-world relevance, and critical thinking into its design.
Our approach
- Dual-language support: Developed a bilingual dataset with questions in English and Malay to promote accessibility for multilingual learners
- Visual grounding: Made it visual by incorporating figures to complement questions and support contextual understanding
- Reasoning-focused: Emphasized reasoning with questions needing problem-solving skills, as opposed to recall of knowledge
- Real-world context: Ensured context for better learning with questions derived from real-world scenarios, such as past SPM (Sijil Pelajaran Malaysia) examinations
- Dual-configuration: Built two datasets with the same features and structure on two configurations—
data_en(English) anddata_ms(Malay)

The results: A new benchmark for reasoning in bilingual STEM AI
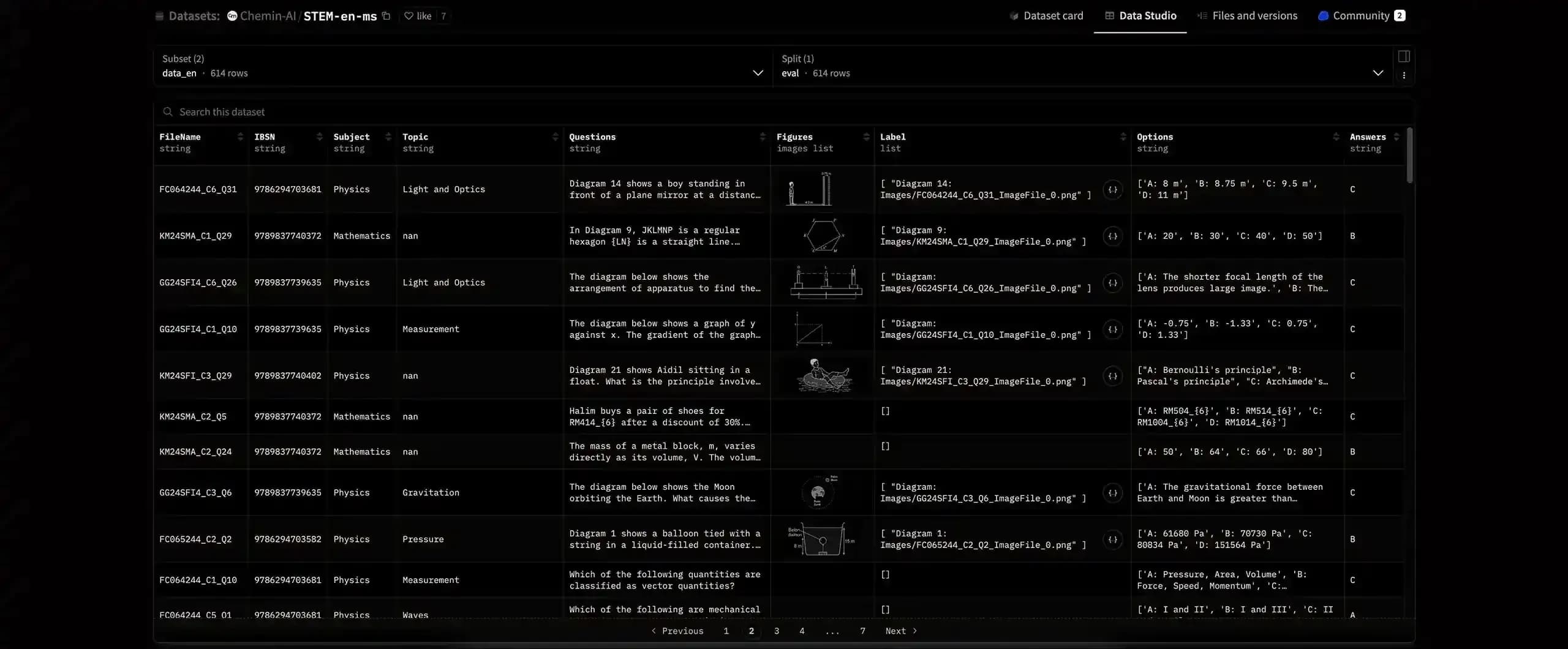
Dataset of 500 dual-language questions in Maths and Physics with data fields including:
- FileName: Unique identifier for the source file (alphanumeric)
- ISBN: International Standard Book Number of the source book (if available)
- Subject: Academic subject (e.g., Physics, Mathematics)
- Topic: Specific topic of the question within the subject (may be missing)
- Questions: Main body of the question or problem statement
- Figures: List of associated image files related to the question (empty if no figures are present)
- Label: Original caption or description of each image in the imgs list
- Options: Possible answer choices for the question, with keys (e.g., "A", "B", "C", "D") and corresponding text
- Answers: Correct answer to the question, represented by the key of the correct option (e.g., "C")
Also included:
- Public leaderboard of model performance analysis based on 5-shot and First Token Accuracy
- Hosted openly on HuggingFace as a benchmark resource for other AI teams
Our curated dataset provides a testbed for reasoning in bilingual STEM AI, supporting more inclusive and language-aware model evaluation.
Make inroads in your industry
Have a use case for AI? Together with our experts, we can curate a unique dataset tailored to your model evaluation needs.
More stories

Turning mission-critical data into waste intelligence
Accelerated waste recognition AI by delivering 1 million high-accuracy, compliance-ready annotations monthly through expert-driven workflows and rapid data turnaround.

Audio AI Annotation for a Premier Gaming Studio: Scaled Output by 294%
Prepared 629.5 hours of conversational audio in 30 days while maintaining 99% accuracy and zero rework.
Gaming Audio Annotation: Structuring Speech Cues at 95%+ Accuracy
Turned emotion, accent, demographic, and speech cues into structured training data for adaptive game AI.