Navigating linguistic nuance for banking conversational AI
1,169+
clips of multilingual audio processed for annotation
96.39%
overall dataset accuracy achieved
3-day
training ramp-up to production readiness
USE CASE
Audio segmentation | Multilingual transcription | Conversational tagging
INDUSTRY
FinTech | Banking Customer Support
SOLUTION
Data Stack
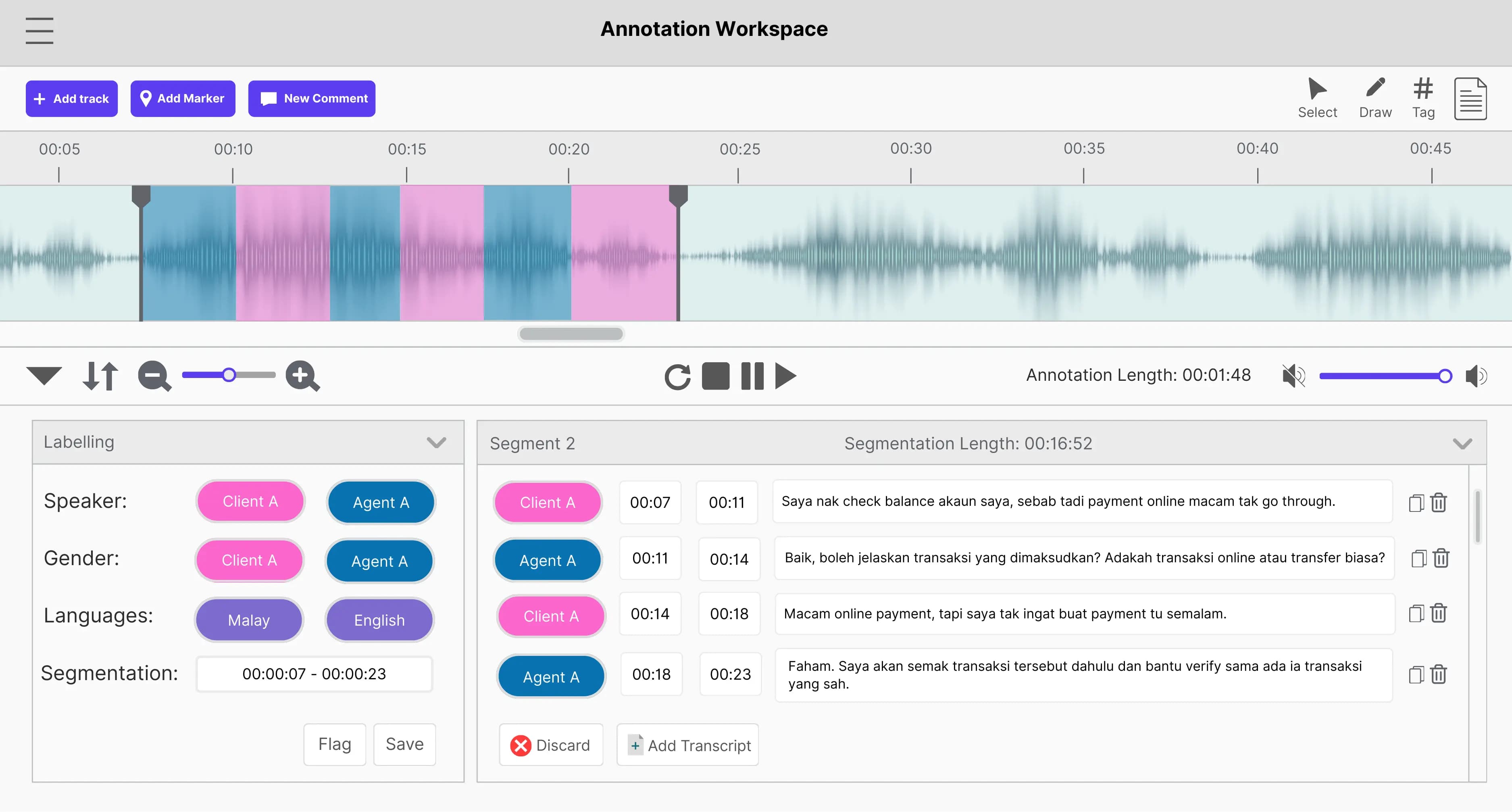
The mission: Turning real banking conversations into usable AI training data
A financial technology client developed a conversational AI system to improve bank customer support and reduce operational costs. To train the model effectively, the dataset needed to reflect natural banking conversations that include dialect variation, code-switching, and informal phrasing. Our role involved converting raw conversational audio into training data by segmenting, transcribing, and tagging it while meeting strict quality requirements.
The challenge: Managing multilingual speech at scale
Multilingual conversational audio introduces complexity that does not appear in structured datasets. Speakers often mix languages, shift between dialects, and use informal particles that are important to meaning but easy to miss during transcription. The project also required a workflow capable of maintaining quality as it scaled a new workforce from scratch.
Key obstacles
- Dialect variation in Malay speech: Regional dialects such as Kelantanese and Kedahan influenced pronunciation and vocabulary.
- Tonal ambiguity in Mandarin: Meaning often depended on tone, requiring careful listening to distinguish similar-sounding words.
- Code-switching between languages: Speakers frequently mixed English, Malay, and Chinese within the same sentence.
- Informal speech and conversational fillers: Particles, such as “lah” and “leh”, needed to be preserved to reflect natural conversation.
- Scaling multilingual annotation teams: Annotators needed strong listening ability and familiarity with mixed-language speech, despite limited prior annotation experience.
- Talent scarcity in specific dialects: Recruiting Cantonese speakers who could both understand and write the dialect proved particularly difficult.
- Evolving workflow requirements: Language priorities and annotation processes shifted during the project.
The goal:
Deliver multilingual conversational datasets with >95% accuracy while ramping a new annotation workforce to production within a short onboarding cycle.
The solution: A promotion-based QC model for multilingual speech data
We built a multilingual annotation team from scratch and introduced a quality-control (QC) model for conversational speech across languages. Rather than separating annotation and review into rigid roles, high-performing annotators were promoted into QC positions. This created a team capable of both executing and reviewing tasks, ensuring the workflow remained accurate as production scaled.
Training focused on practical listening exercises using real conversational audio, helping annotators quickly learn how to handle dialect variation, code-switching, and informal speech patterns.
This structure allowed the project to stabilize quality early while adapting to changing requirements and language priorities.
Our approach:
- Parallel onboarding across languages: Training was reduced from 7 days to 3 days by running English–Malay and Mandarin workflows simultaneously.
- Promotion-based QC structure: Top-performing annotators moved into review roles, creating a layered verification system across the team.
- Verbatim transcription standards: Annotators followed a strict rule to transcribe speech exactly as heard, preserving slang, fillers, and language mixing.
- Continuous feedback loops: Common errors and edge cases were documented and discussed during office hours to keep the team aligned.
The results: High-accuracy multilingual speech datasets for banking AI
- 96.39% overall dataset accuracy, exceeding the client’s 95% threshold.
- 1,169 multilingual audio clips processed across Malay and Mandarin workflows.
- Stable production quality was achieved within the first two annotation batches, allowing the team to move quickly into full production.
- Dataset submissions were accepted on the first pass in nearly every batch, minimizing rework and delivery delays.
- The project expanded from a 4-hour pilot to more than 80 hours of multilingual audio collection, demonstrating the scalability of the workflow.
- Training ramp-up was reduced from 7 days to 3 days, enabling faster onboarding of new annotators as the dataset volume increased.
The project established a repeatable workflow for annotating multilingual conversational speech while maintaining strict accuracy requirements for financial AI systems.
Bridge the gap between dialect and data
Banking customers rarely speak in scripts. We resolve dialect variation and language mixing, turning informal speech into structured datasets that help conversational AI perform reliably in financial services and other high-stakes environments.
More stories

Solving language blind spots with culturally fluent AI
Engaged multilingual Asian talents to capture local language and cultural nuance, accelerating high-accuracy training for an AI communication model.

Driving rapid throughput of validated data to power global agri-tech
Designed an extensible AI annotation verification infrastructure for the client's data labeling team to meet high demands and seasonal surges.

Enhancing high-stakes autonomous systems with contextual fidelity
Enabled precise and context-appropriate recognition in an autonomous driving system through custom data labeling and AI annotation process.