Structuring subjectivity to power next-gen Audio AI
250+
hours of conversational audio prepared for training
>95%
model accuracy achieved
3-day
ramp-up from training to production
USE CASE
Emotional tagging | Accent and demographic labeling | Audio segmentation | Audio transcription
INDUSTRY
Interactive Entertainment | Conversational AI
SOLUTION
Data Stack
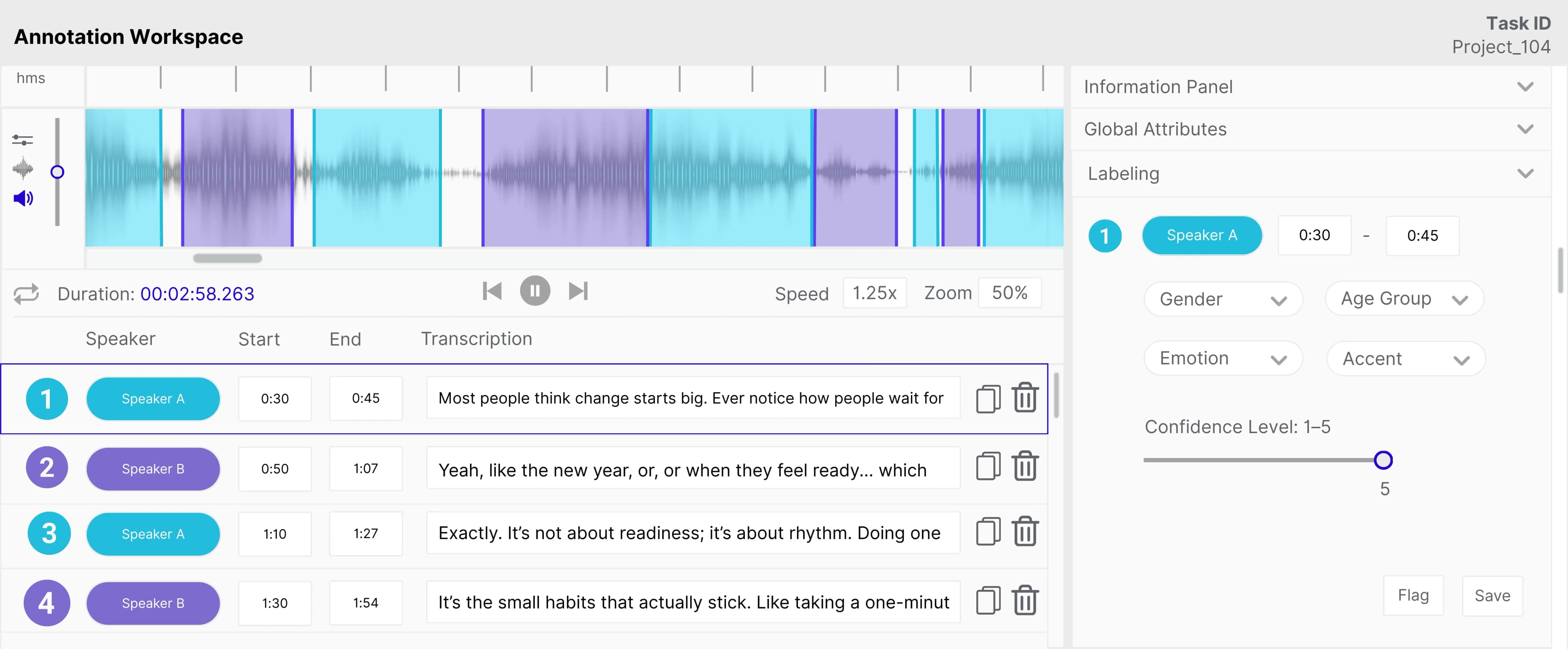
The mission: Transform diverse, high-variability speech into structured, auditable training data
A global gaming company set out to develop conversational AI characters capable of understanding and responding to human voices with emotional precision. Achieving this required converting raw audio from podcasts and films into training data that spanned multiple accents, age groups, genders, and emotional states. This highly subjective environment and fragmented data landscape became the core challenge our team set out to solve.
The challenge: Breaking the inconsistency barrier in speech annotation
Converting more than 250 hours of diverse speech into reliable training data was not just a volume challenge. Conversational AI demands precise, consistent labels for emotion, accent, demographic, and background cues. Yet, the process from raw audio to reliable data was fragmented. Feedback lacked structure, rules shifted mid-stream, and annotators had no unified reference point for quality.
Key obstacles
- Unstructured feedback: Comments lacked clear metrics or scoring, making it difficult to assess accuracy or target improvements.
- Reviewer subjectivity: Feedback varied widely among reviewers, resulting in inconsistent weighting and acceptance of similar errors.
- Shifting task definitions: Frequent updates to emotion categories, transcription rules, and labeling criteria disrupted standardization and required rapid recalibration.
- Undefined benchmark: Quality expectations and tagging standards were not consistently defined, leaving annotators without a clear reference for expected output.
- Complex audio edge cases: Overlapping dialogue, rapid speech, and intrusive background noise made precise transcription, segmentation, and event tagging more difficult.
The goal
Build a fast-ramp audio labeling pipeline that converts diverse, unstructured speech into structured and verifiable training data for conversational AI.
The solution: Rapidly building a structured pipeline to transform complex speech data
Within a week, we launched a complete workflow that moved seamlessly from training to production to upskilling. Nearly 70 annotators joined the initial training phase, from which the top 15 to 20 were selected for deployment. Training lasted 3 days and focused on audio segmentation, transcription, and emotional tagging. Most trainees had strong language skills but limited experience with audio annotation, so sessions emphasized real-world tasks and guided practice.
Once production began, top performers advanced into quality control roles, creating a self-sustaining two-tier review system where every task was checked before submission. This approach ensured accuracy, consistency, and scalability from day one.
Our approach
- Scaled a multi-tier team of annotators, QA, and training leads to manage hundreds of hours of complex audio across multiple formats.
- Established taxonomies and client-approved reference libraries to translate shifting guidelines into consistent, actionable standards.
- Reduce ramp-up time to under 3 days through hands-on training on audio segmentation and transcription, reinforced by live task supervision.
- Applied a two-tier review system combining full QC checks and targeted spot reviews by team leads to maintain consistency and resolve ambiguous cases.
- Tracked internal quality metrics to identify bottlenecks, measure progress, and provide transparent updates to the client.
The results: People-driven precision at scale
- Stood up a production-ready pipeline in under seven days, aligning 50+ trained annotators and 20+ QA leads on consistent standards across 250+ hours of speech.
- Achieved over 95% accuracy across emotional tagging, accent and demographic labeling, audio segmentation, and transcription within the first month of the project.
- Quality improved by an average of 13.28% per retraining cycle.
- Calibration time for 10 hours of audio dropped from 6 days to 3 as the quality control team expanded from 6 to 18 within the first week of production.
This transformed a shifting, high-subjectivity task into a stable, repeatable pipeline that delivers high-confidence audio data and a blueprint for scaling nuanced data labeling across future multimodal projects.
Power lifelike conversations in every AI interaction
Every voice carries detail. We capture those layers through precise annotation, turning emotion, accent, and context into structured data your models can truly learn from.
More stories

Solving language blind spots with culturally fluent AI
Engaged multilingual Asian talents to capture local language and cultural nuance, accelerating high-accuracy training for an AI communication model.

Driving rapid throughput of validated data to power global agri-tech
Designed an extensible AI annotation verification infrastructure for the client's data labeling team to meet high demands and seasonal surges.

Enhancing high-stakes autonomous systems with contextual fidelity
Enabled precise and context-appropriate recognition in an autonomous driving system through custom data labeling and AI annotation process.