Lessons from Building AI Agents in Client-Critical Workflows
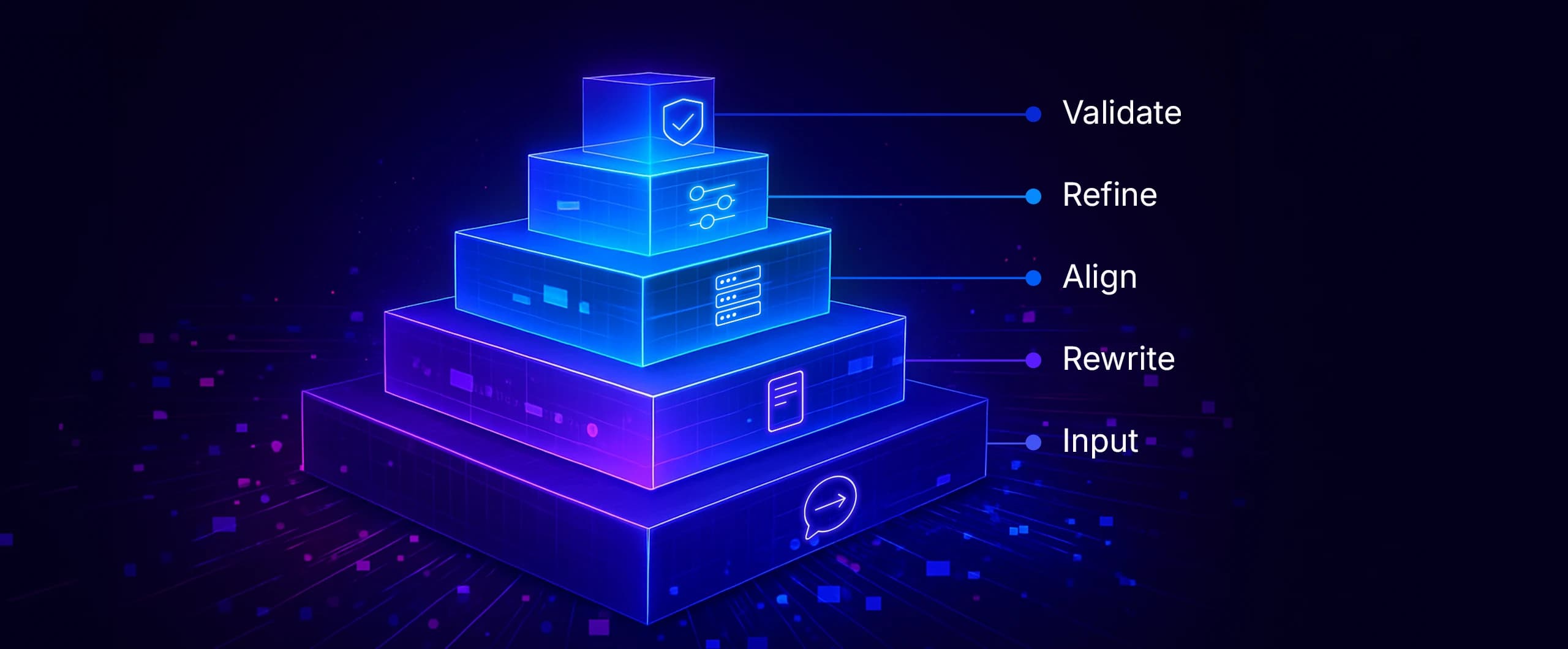
When AI Hits Production
AI agents are closing the gap between experimentation and production faster than most teams can handle. They now take on workloads that once required large, specialized teams.
Production demands operational stability under pressure, at scale, with real clients depending on the output. That standard is far harder to meet than any benchmark.
Most AI deployments fail because the surrounding architecture can’t handle production conditions. Production introduces inconsistent data, edge cases, and volume spikes. Errors compound quickly, and tolerance drops to zero.
This shaped how Chemin designs production systems.
What We Built: An Automation-First AI Workflow
We deployed an automation-first workflow for a multilingual rewriting project. The project involved long conversational histories, mixed-language inputs, and strict linguistic requirements at high volume.
Led by Delivery Project Manager Aisyah, the system rewrote assistant responses across extended dialogues. It enforced linguistic and factual standards through a staged automation pipeline with minimal manual oversight.
"I sit at the intersection of delivery and systems. I build automated pipelines that process data at scale. My job is to ensure our work flows end-to-end without breaking, even when volume scales”. — Aisyah, Delivery Project Manager
Traditionally, this would require a large annotation team and multiple quality control rounds. We replaced annotator tasks with staged processing, validation checkpoints, and rule-based safeguards.
Results At Production Scale
The results were measurable:
- Efficiency: 97% reduction in manual handling time (~15 minutes -> ~30 seconds).
- Turnaround: Under 7-day delivery time, weeks compressed into days.
- Resource Leverage: 10x increase in processing capacity, without additional overhead.
As execution accelerated, inconsistencies surfaced faster. Stability depended on whether the system could isolate and contain errors before they spread.
1. AI Production Redefines Quality Standards
Variation Is The Default State
Production data is inconsistent by nature. Responses vary in structure, language, tone, and clarity.
Many outputs depended on long conversational histories. Small inconsistencies scaled into systemic issues.
"In live delivery, near-correct is still broken. Ambiguity becomes expensive at scale.”
Figure 1. Anatomy of a Production Workflow

A single agent can't manage this level of variation reliably. The system must divide responsibilities into clear stages.
2. Scalable AI Systems Require Decomposition
Why Single-Agent Systems Break
In controlled environments, large prompts can produce strong outputs. In production, combining tone, reasoning, and formatting into one step reduces control.
Errors become harder to trace. Small deviations spread across batches.
Staged AI Pipelines For Control
We decomposed the workflow into specialized agents. Each stage handles a single responsibility:
- Rewriting
- Reasoning alignment
- Validation and refinement
"Delivery is a chain of decisions. Breaking it into explicit steps made the system controllable."
Figure 2. Staged Decision Architecture

This structure makes failures visible and correctable. It also improves auditability across the workflow.
Model Specialization
Different models handle different stages, each within strict task boundaries, using single-responsibility prompts. This allows teams to trace issues to specific stages and fix them without disrupting the entire system.
3. Automation Increases Speed And Risk
Automation removes manual buffers. Errors reach production faster.
"The risk isn't that automation makes errors, humans do too, but that automation makes errors fast," Aisyah explains.
At scale, fixing errors becomes expensive. Corrections require batch-level rollback and revalidation, not manual edits.
Designing For Containment
Risk containment is a structural requirement. We embedded three control layers directly into the workflow:
- Rule-Based Validation: Detects structural drift in real time using an automated validation script.
- Automated Stop Conditions: Halts execution when error thresholds are reached within a batch.
- Stage-Level Checkpoints: Verifies outputs between each processing step.
Containment ensures scale improves efficiency, not error propagation.
4. Move Judgment Into System Design
AI agents execute predefined logic. They don't resolve ambiguity on their own.
During deployment, ambiguity surfaced in:
- Factual corrections within long assistant responses.
- Mixed-language normalization without flattening tone.
- Edge case handling under strict linguistic constraints.
Without clear rules, outputs diverged across batches.
Encoding Decisions Before Execution
At Chemin, human expertise is applied during workflow construction. Before deployment, we define:
- Acceptable Output Criteria: Clear standards for tone, factual accuracy, and linguistic normalization.
- Escalation Thresholds: Conditions that trigger human review when the system detects uncertainty.
- Edge Case Strategies: Predefined logic for complex or ambiguous inputs.
This ensures consistent execution at scale.
5. Reliability Is A Continuous Discipline
Production reveals behavior that design can't predict. As volume increased, new edge cases emerged, and validation rules required adjustment. Stability was maintained through calibration, not assumed at launch.
System Calibration In Practice
Safeguards evolved as scale revealed new behavior:
- Stop Condition Tuning: Adjusted based on early performance signals.
- Validation Refinement: Rules strengthened to catch emerging drift mid-project.
- Escalation Optimization: Reduced unnecessary interruptions while preserving safety flags.
These refinements were possible because the system was version-controlled and reversible. Adjustments could be tested and deployed without disrupting delivery.
Engineering Reliable AI Systems
Moving from AI experimentation to production changes how success is measured.
Reliable AI systems share three traits:
- Clear decision boundaries
- Structured validation layers
- Built-in containment mechanisms
At Chemin, AI systems are designed to stay accountable under pressure. Deployment success is measured during execution, not in testing.
AI earns the right to scale by remaining stable inside the workflows clients depend on.
Key Takeaways
- Workflow architecture determines reliability: Clear task boundaries and validation layers keep outputs stable.
- Decomposition enables control: Separate stages make systems observable and correctable.
- Containment prevents system-wide failure: Stop conditions and checkpoints limit error propagation.
- Decisions must be defined before execution: Systems follow rules. They don't infer intent.
- Reliability improves through iteration: Continuous calibration is required as new patterns emerge.
Strategic AI Operations
Reliable AI systems require more than strong models. They require structured workflows, controlled execution, and clear accountability.
For organizations deploying AI agents in client-critical environments, architecture determines outcomes.
To explore production-grade AI workflows and deployment strategies, connect with the Chemin team or review our case studies.
Discover more
Global vs Local: Testing GPT-4o-mini and SEA-LIONv3 on Bahasa Indonesia
We tested two Large Language Models (LLMs), GPT-4o-mini and SEA-LIONv3, on their handling of Indonesian-specific questions.
Chemin's Bilingual Dataset for Evaluating Reasoning Skills in STEM Subjects
Fresh out of the oven! Our team just released a bilingual multimodal dataset for evaluating reasoning skills in STEM Subjects.

Press Release: TDCX and SUPA tie-up to help companies address a key barrier in generative AI adoption
Collaboration provides companies with a one-stop-solution for their data labeling needs.