Zero Rework at Scale: How We Stabilized Audio AI Production
Building on our initial success, Chemin has reached a new operational milestone.
In audio AI production, rework is the silent tax. Ambiguous guidelines and misaligned annotation standards slow everything down.
What started as a 250-hour pilot is now a multi-regional audio AI pipeline. It delivers consistent, high-accuracy emotional and linguistic datasets at scale.
This pipeline supports interactive voice AI in gaming, where systems must recognize emotion, accent, and conversational nuance in real time. Training these systems requires structured datasets that balance variability with strict consistency across transcription, segmentation, and emotional tagging.
In the first phase, we achieved 95%+ model accuracy with a 3-day ramp from training to production. In January, every batch passed the client audit without resubmission.
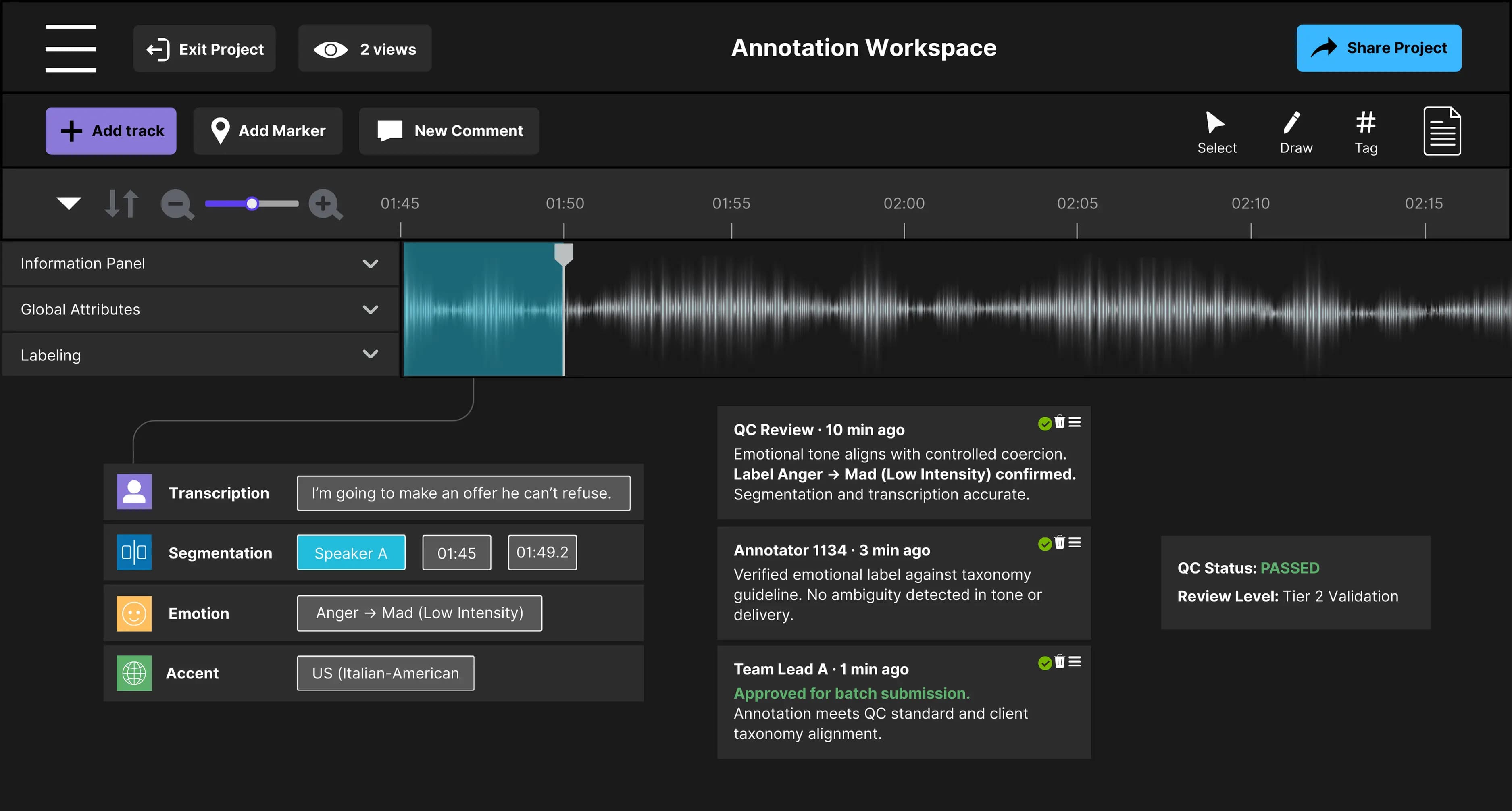
Figure 1. Example of a fully validated annotation passing quality control.

A completed annotation with transcription, segmentation, emotion, and accent labels validated through QC review before batch submission.
Phase One: Structuring Subjectivity
The first phase focused on stabilizing a highly subjective audio data environment. Source material included podcasts and film dialogue with overlapping speech, rapid emotional shifts, and diverse accents.
Without a unified framework, annotators interpreted emotional tone, segmentation boundaries, and transcription rules differently. This created fragmented feedback loops and inconsistent output quality.
Figure 2. QC Review: Flagging an Incorrect Emotion Classification

An annotator initially classified the line under Fear → Anxious (Low Intensity). During QC review, the label was flagged because the delivery conveys external coercion rather than internal uncertainty. The task is returned for revision to align with the project’s emotional taxonomy.
We replaced interpretation with structured governance.
Four controls anchored the system:
- Standardized taxonomy: Emotional and linguistic labels aligned to client expectations
- Live-task simulation: Training inside the production environment to reduce ramp time
- Two-tier review system: High-performing annotators advanced into QC roles
- Mandatory onboarding: Video-based training to standardize baseline understanding
Within one month, calibration time for 10 hours of audio dropped from 6 days to 3 days. The workflow shifted from individual judgment to repeatable system behavior.
Phase Two: The January Inflection Point
As throughput increased, one question defined the next phase: Can we scale without rework?
We define Zero Rework as full batch acceptance after a 20% client audit, with no resubmission required.
In January, every batch passed on first review:
| Month | Rework Rate |
|---|---|
| November | 40% |
| December | 18.75% |
| January | 0% |
The shift came from moving quality control upstream. Guideline gaps and edge cases were resolved before submission.
This removed feedback loops that previously delayed delivery. Timelines became predictable as the system scaled.
"Scaling is not about doing more work. It’s about building systems that make good work repeatable. Structure reduces friction. Clear standards reduce ambiguity. Defined roles reduce confusion." — Muhammad Azizi, Team Lead
Engineering A Multi-Regional Audio AI Pipeline
To support growth, we scaled to ~180 personnel across Asia and LATAM. The system operated on a structured review path designed for consistency at scale.
Each layer enforced accountability:
- Execution discipline: Controlled batching with assigned Team Lead oversight.
- Tiered validation: Annotator → QC → Team Lead validation before submission
- Structured escalation: Edge cases routed through formal client query channels.
- Coverage control: Full QC in early stages, then targeted audit sampling.
- Final assurance: Batch-level validation before client delivery.
Asia remains the primary production base. LATAM operates independently under the same governance model, enabling a 24-hour production cycle.
Managing Complexity As Data Scales
Dataset complexity increased as audio length expanded up to 10-minute clips. Longer duration raised transcription load and introduced a higher risk of attention fatigue.
We introduced a weighted accuracy framework to prioritize critical components:
| Component | Weight |
|---|---|
| Transcription | 55% |
| Segmentation | 30% |
| Labeling | 15% |
This structure focused effort on high-impact areas while maintaining consistency across the dataset.
The system reduced overcorrection and preserved core data integrity as complexity increased.
"True readiness for scaling occurs when high-quality output and team morale are in sync with stabilized procedures. When the entire team is aligned on these standards, we can move upward with confidence." — Rudy She, QC Lead
Stabilizing Performance Before Scaling Further
Scaling required alignment across output quality and team behavior.
High-quality production depends on clear standards, stable workflows, and consistent feedback loops. Teams must operate within defined structures before increasing volume.
We resolved potential drift during early dataset phases. This ensured production stability before introducing additional complexity.
Scaling Toward the 1,000-Hour Milestone
Scaling to 1,000 hours per month requires replication of proven systems.
The same controls that eliminated rework now govern growth:
- Controlled batching
- Tiered validation
- Upstream escalation
- Continuous calibration
This system maintains predictable throughput and defensible quality as data variability increases.
Reliable audio AI production depends on structured workflows that capture emotional nuance without sacrificing consistency.
From Subjectivity to System Design
At scale, audio AI pipelines fail at the system level, not the task level.
Ambiguity in guidelines, inconsistent review paths, and fragmented feedback loops introduce hidden instability. These failures compound as volume increases.
Chemin’s approach focuses on governance, structure, and repeatability.
We transform subjective human speech into structured, auditable training data for production-grade AI systems. If your current pipeline depends on manual interpretation or reactive QA, it will not scale predictably.
Connect with us to evaluate your audio AI workflow or launch a structured pilot for global-scale production.
Discover more
Global vs Local: Testing GPT-4o-mini and SEA-LIONv3 on Bahasa Indonesia
We tested two Large Language Models (LLMs), GPT-4o-mini and SEA-LIONv3, on their handling of Indonesian-specific questions.
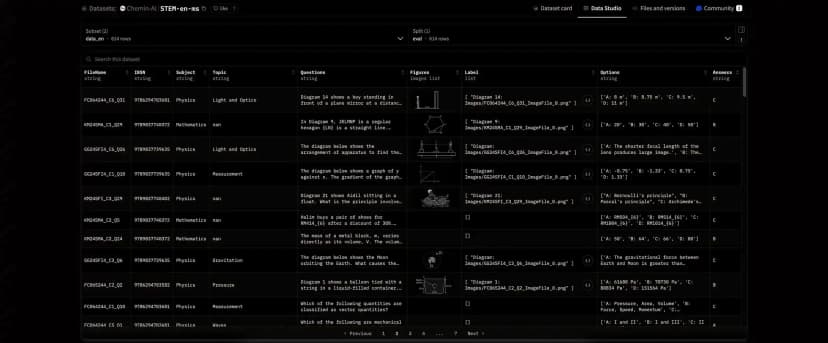
Chemin's Bilingual Dataset for Evaluating Reasoning Skills in STEM Subjects
Fresh out of the oven! Our team just released a bilingual multimodal dataset for evaluating reasoning skills in STEM Subjects.

Press Release: TDCX and SUPA tie-up to help companies address a key barrier in generative AI adoption
Collaboration provides companies with a one-stop-solution for their data labeling needs.