The New Sound of Gaming: How Audio AI Powers Reactive Player-Aware Worlds

Voice Is Becoming the New Game Interface
AI gaming investments hit $3.1 billion in Q1 2025, and much of that capital is flowing toward one shift: using voice as an interaction layer rather than a cinematic feature.
Ubisoft's recent Teammates project demonstrates how spoken commands alter squad tactics, with NPCs adjusting their positions and support actions in real-time. Ubisoft's earlier Neo NPC prototypes (with Nvidia and Inworld) tested improvised conversation but struggled with scene awareness. Tools like the Fortnite Persona Device push the boundary further by enabling creators to build NPCs that respond to tone, phrasing, and emotional cues.
These experiments point in the same direction: voice is moving from a narrative accessory to a core control surface. As games rely more on real-time listening, even minor interpretation errors can disrupt pacing, break combat flow, or undermine player intent.
Chemin views this as evidence that reactive Audio AI must be developed with deliberate governance, grounded in calibration, speech diversity, and human oversight, so it behaves predictably across global players.
Why Games Still Struggle to Understand Players
Real-time voice interpretation remains one of the hardest problems in game AI. Models may generate fluent dialogue, but still struggle to accurately read timing, tone, and speech diversity, leading to broken scenes and a loss of trust.
Timing Lag Breaks Immersion
Latency, the delay between a player speaking and the character responding, is the first point where reactive audio breaks down. A player-action latency study reports sensitivity at 25–60 ms, whereas a separate performance-impact study shows a sharp drop around 100 ms. Voice-driven systems must respond almost instantly to match the speed and emotional intensity of gameplay.
Gameplay impact: Delayed reactions, misread cues, and commands that fail in critical moments.
Emotional Cues Are Often Misread
Research from Feeling Machines reveals that emotional expression varies across cultural, personal, and situational contexts. Without this nuance, Audio AI often confuses urgency, excitement, or frustration.
Gameplay impact: Escalated tensions, mismatched tone, and emotional reactions that break immersion.
Speech Diversity Overwhelms Models
In real gameplay, accuracy often breaks down when players code-switch, use slang, or shift rhythm under pressure, patterns that are often missing from most Western training data. This is why models that score 60–70% on controlled samples drop to 9% on live in-game audio. This drop-off reveals how brittle current systems become when faced with unscripted, high-pressure player speech.
Gameplay impact: Ignored commands, incorrect triggers, and lost intent during high-pressure moments.
The Foundations of Trustworthy Audio AI
Reactive Audio AI only succeeds when players feel understood. That confidence comes from the principles that shape models long before they reach a game: data lineage, speech diversity, calibrated emotion modeling, and robust governance.
Clear Data Lineage Builds Predictable Behavior
In Cyberpunk 2077: Phantom Liberty, the Respeecher team used verified studio recordings, family-approved consent, and controlled voice conversion to preserve Miłogost Reczek's performance without unintended drift. This refers to subtle changes in vocal character or emotion that no longer match the original performance. Predictable audio begins with verified provenance, rather than patching mistakes later.
Accent-Inclusive Datasets Reduce Misinterpretation
Predictable behavior in live gameplay depends heavily on how well models interpret global speech patterns. East Asian game localization research suggests that Western-trained models frequently misinterpret shortened phrases, rhythm changes, and tonal emphasis in Southeast Asian and East Asian speech, unless the datasets reflect regional delivery styles.
Bias-Tested Emotion Models Prevent Incorrect Reactions
Emotion models determine how NPCs escalate, reassure, or respond under pressure. Cultural insights on souls-like games note that players naturally adjust tone when stressed or deeply immersed. Testing across diverse vocal styles ensures that NPC reactions align with player intent, rather than relying on cultural assumptions.
Safety Checks Keep Multiplayer Voice Fair
Multiplayer voice adds risk because reactive models still struggle to separate intensity from actual harm. ToxMod demonstrates that tone, sentiment, and context must be evaluated together. Riot's comms restriction and audio retention framework relies on short-term voice capture, explicit escalation rules for when clips can be reviewed, and strict deletion windows that prevent unnecessary storage, allowing effective moderation without creating long-term voice archives.
Complementing this, the Systems Health: Voice & Chat Toxicity update details how voice evaluation, behavioral ratings, and post-match reviews create consistency across penalties.
Together, these practices prove that multiplayer safety depends on predictable rules, measured judgment, and transparent handling of voice data, rather than fully automated interventions.
What Trust Looks Like in Production
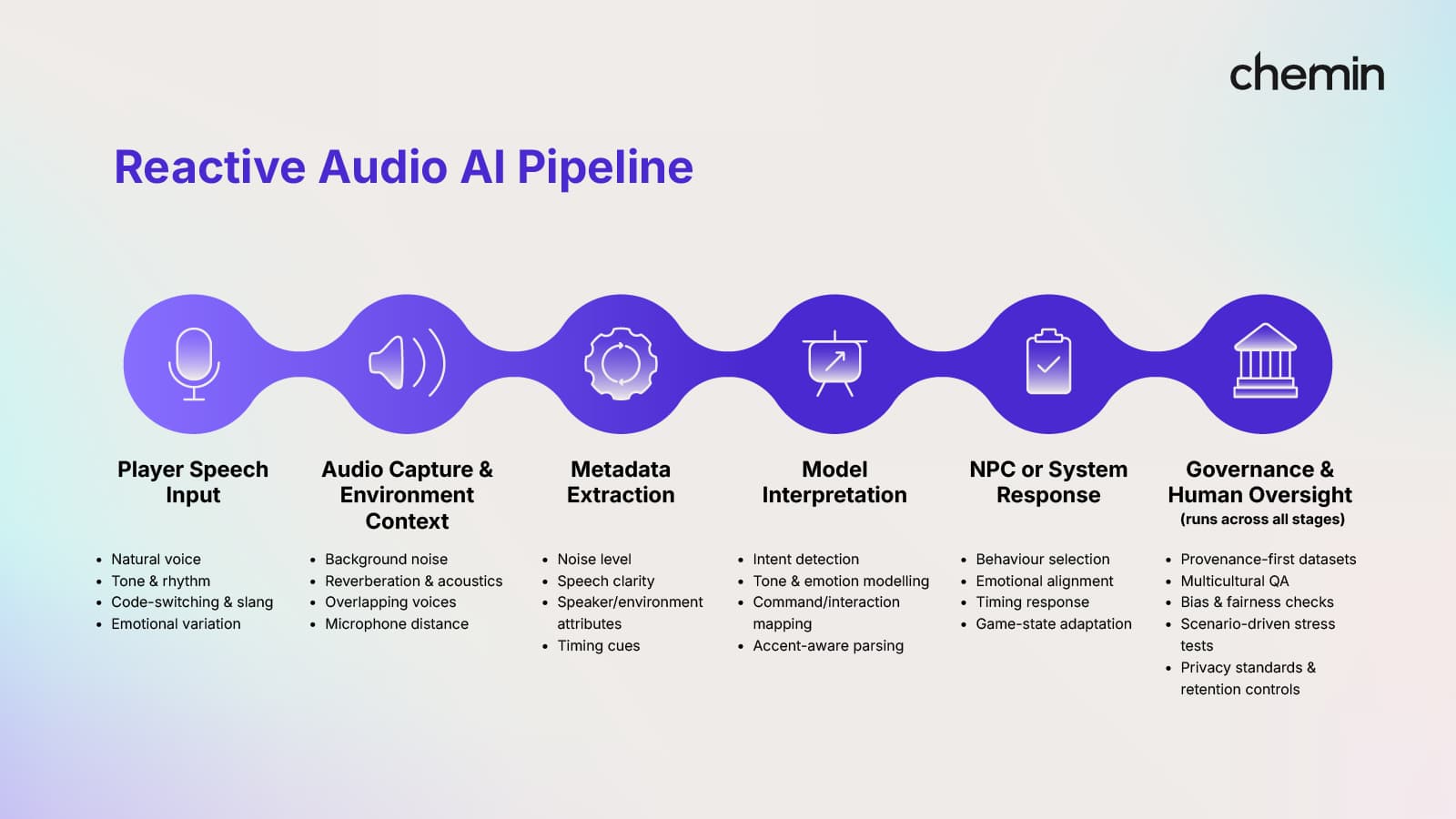
Figure 1. Reactive Audio AI Pipeline in Production
Reactive characters become believable when the game consistently reads timing, tone, and intent. That reliability stems from how studios structure their data and evaluation before deploying any in-game content.
Annotation Shapes How NPCs Understand Players
Annotation defines tone, urgency, sarcasm, rhythm, and intent. Research on speech-emotion systems in serious games reveals that high-energy states (joy, stress, anger) are frequently misclassified unless labels capture expressive and cultural nuance. Precise annotation allows NPCs to respond to intention rather than surface phrasing. Ultimately, good annotation becomes the design language NPCs use to interpret human intention.
Metadata Adds the Missing Context
Environmental-audio research suggests that background noise, room acoustics, and overlapping sounds all influence how urgency and intent are conveyed. In raids, storms, machinery zones, or fast-paced combat, players speak louder or more softly, and models trained on clean audio often misread these cues.
Metadata captures noise levels, distance, speech clarity, and environmental type, helping Audio AI maintain steady reactions even when gameplay becomes chaotic.
Stress Tests Expose Real-World Failure Points
Live gameplay pushes speech into louder, faster, mixed, interrupted, or breathless patterns. These extreme conditions surface errors that never appear in studio-clean recordings. Stress tests stimulate overlapping voices, volume spikes, mixed languages, and chaotic environmental noise to expose misinterpretations or delayed reactions long before players encounter them in real-world situations. Research on acoustic variation shows that even small context cues can alter predictions or introduce reaction delays, precisely the moments when governance becomes essential.
Human Expertise Guides the Final Decisions
Even the strongest Audio AI benefits from human judgment. Experts refine emotion baselines, correct interpretation drift, evaluate performance across accents and cultures, and guarantee reactions align with the studio's narrative intent.
Human oversight ensures that:
- Escalation feels fair.
- Emotional tone remains consistent.
- Cultural nuance is respected.
- NPC behavior matches narrative goals.
- Privacy and provenance standards are upheld.
This is where Chemin anchors its contribution: provenance-first datasets, multicultural QA teams, dedicated bias testing, and scenario-driven evaluation that help studios operationalize governance and deliver Audio AI that behaves predictably in real gameplay.
Key frameworks, such as IMDA AI Verify, multiplayer voice anomaly detection, and privacy-aware tools like NVIDIA ACE, show that the industry is moving toward transparent and accountable audio pipelines.
The Conditions That Make Audio AI Worth Relying On
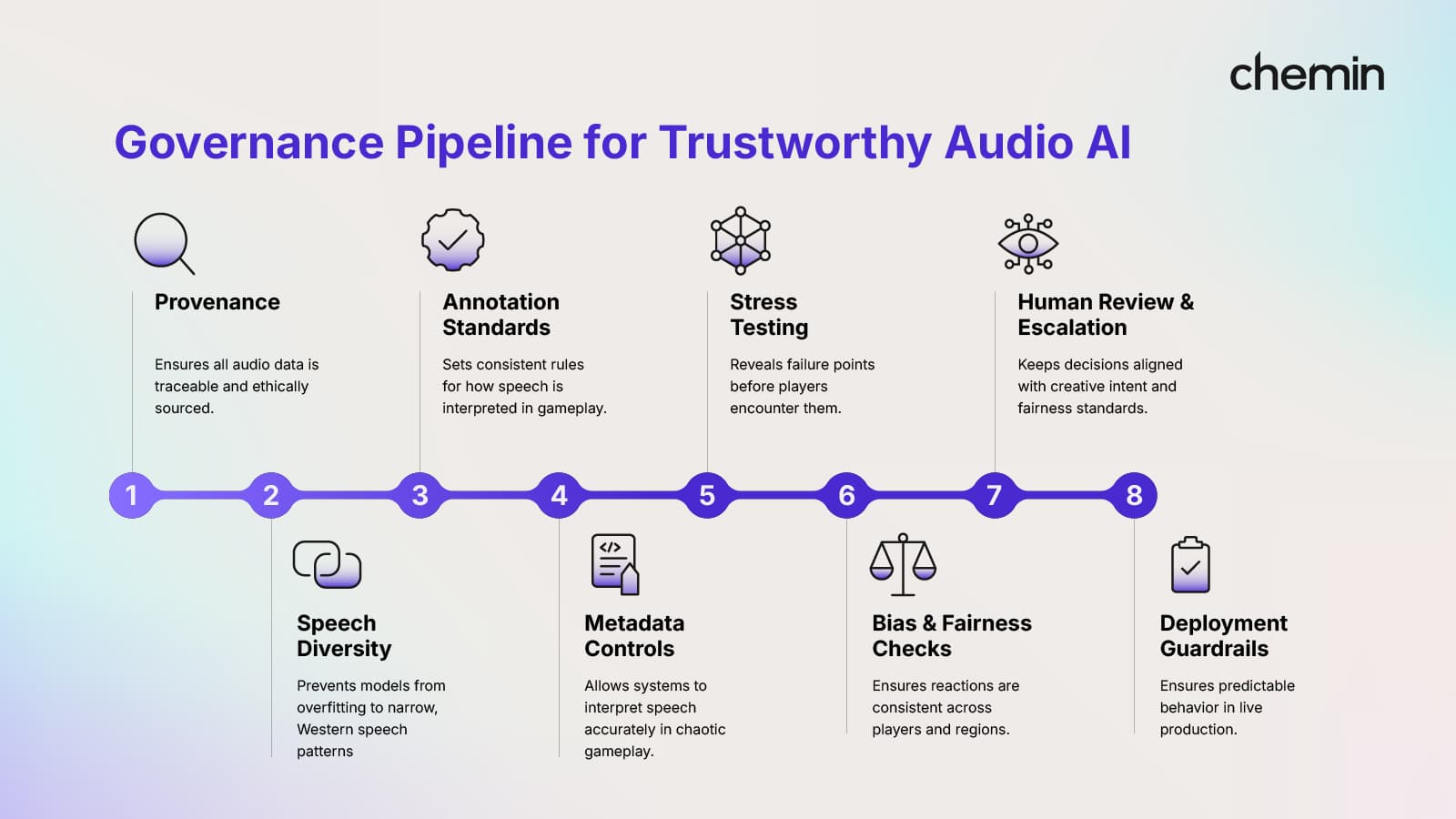
Figure 2. Governance Pipeline for Trustworthy Audio AI
Together, transparent data lineage, diverse speech coverage, and consistent human oversight form the foundation of trustworthy Audio AI. Governance isn't something bolted on at the end; it's the structure that enables accurate, culturally aware listening.
When studios establish clear guidelines for how games convey tone, timing, and context across languages and stress conditions, the technology becomes more stable, interactions feel fairer, and the experience feels more human.
Chemin collaborates with global studios to implement these principles in practice, from provenance-first datasets to multicultural evaluation pipelines.
If your studio is building voice-driven characters or multiplayer systems, talk to us about building Audio AI players that can be trusted.
Discover more
Global vs Local: Testing GPT-4o-mini and SEA-LIONv3 on Bahasa Indonesia
We tested two Large Language Models (LLMs), GPT-4o-mini and SEA-LIONv3, on their handling of Indonesian-specific questions.
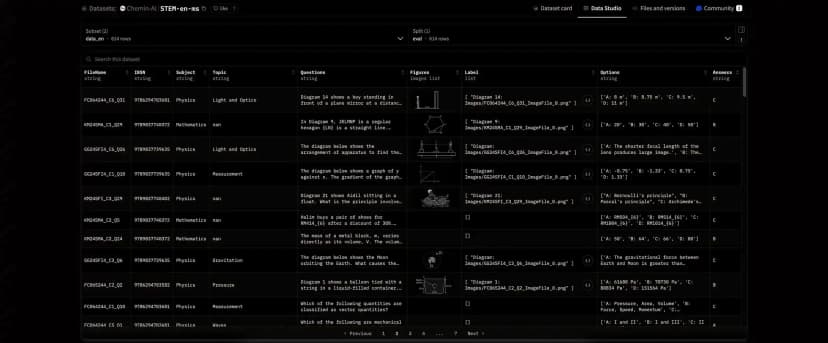
Chemin's Bilingual Dataset for Evaluating Reasoning Skills in STEM Subjects
Fresh out of the oven! Our team just released a bilingual multimodal dataset for evaluating reasoning skills in STEM Subjects.

Press Release: TDCX and SUPA tie-up to help companies address a key barrier in generative AI adoption
Collaboration provides companies with a one-stop-solution for their data labeling needs.