RAG Pipelines Explained: How AI Finds and Uses Your Data
Executive Summary
A language model can sound confident, but it doesn’t know your data. It generates responses from training data that quickly become outdated. Retrieval-Augmented Generation (RAG) solves this by connecting the model to your own information.
Before generating a response, the RAG system retrieves relevant content from documents, databases, or other sources. This makes outputs more accurate and grounded.
At Chemin, we work across the data supply chain: from how information is structured and maintained to how it flows into AI systems.
In practice, RAG pipelines take three common forms:
- Basic RAG: Retrieves information to answer questions.
- Application RAG: Connects AI to business systems and workflows.
- Agentic RAG: Supports multi-step decisions and actions.
Most RAG failures trace back to how data is prepared, retrieved, and used. This article explains how RAG works, where it breaks, and how it applies across real-world systems.
1. Why AI Needs Access To Your Data
1.1 The Illusion of Understanding In AI Systems
A language model generates text by predicting the next most likely token. These predictions come from statistical patterns learned during training, not from real-time fact verification.
When a model explains a topic, it produces a likely continuation of the prompt rather than a verified answer. This works for general knowledge, but breaks down when answers depend on specific or internal information.
Without access to live data, the model generates plausible responses from training patterns rather than facts. The output can look correct while being entirely disconnected from the source. This creates an illusion of understanding.
1.2 When AI Lacks Access To Real Data
Most AI systems don’t have direct access to the data they need to operate accurately. They rely on training data that quickly becomes outdated as documents, pricing, and policies change.
A model trained on past data can’t reflect those updates. It produces responses that sound correct but miss what applies to a specific user or moment.
Without access to live data, outputs may appear usable but can’t be relied on for real decisions.
1.3 RAG As The Layer That Grounds AI Responses
RAG allows AI systems to retrieve relevant data before generating a response. This grounds outputs in real and current information rather than stale training data.
Early RAG research introduced the concept of combining parametric memory (what the model learned) with non-parametric memory (external data sources). This approach improves factual accuracy and reduces unsupported answers.
The retrieval step becomes a core layer that determines what information the model can access. It shapes every response that follows.
Modern RAG implementations extend this into full pipelines. Data is prepared, indexed, and retrieved through vector databases and orchestration layers like LangChain or LlamaIndex.
2. How A Basic RAG Pipeline Works
2.1 From Stored Data to Generated Answers
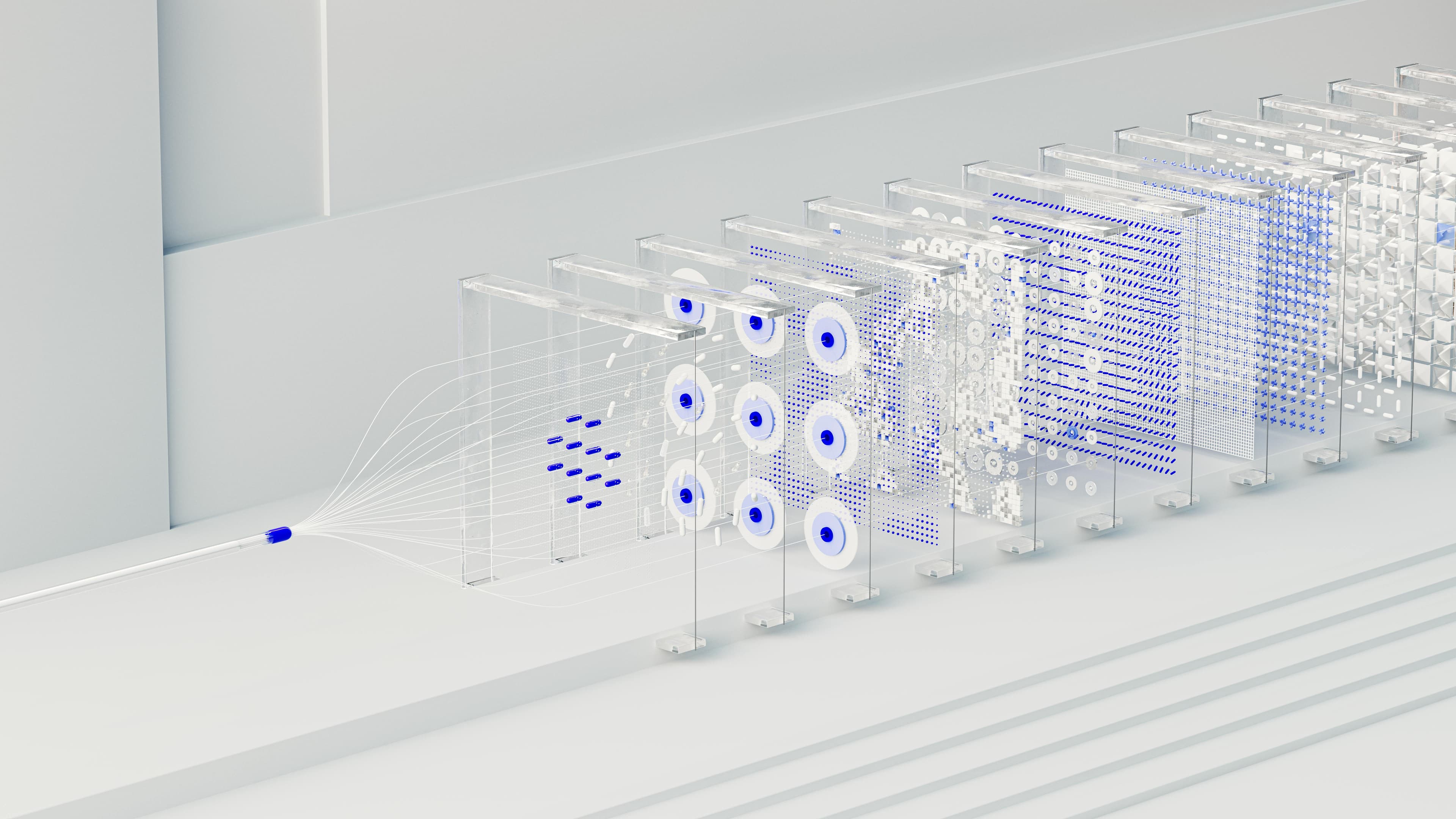
A RAG system works by selecting and assembling the information the model uses to respond.
Figure 1. How a RAG Pipeline Produces an Answer
 A RAG system doesn’t generate responses from memory alone. It retrieves and assembles external information before generation. The final output depends entirely on what is selected and passed into the model.
A RAG system doesn’t generate responses from memory alone. It retrieves and assembles external information before generation. The final output depends entirely on what is selected and passed into the model.
The process follows a sequence:
- Chunking: Data is split into smaller pieces so the system can match relevant sections to a query.
- Retrieval: The system selects the most relevant chunks using vector similarity search, matching meaning rather than exact keywords.
- Hybrid Retrieval: Many production RAG systems combine embedding-based and keyword-based methods to improve precision.
- Generation: The model produces a response using the retrieved information. Output quality reflects what the system receives.
Figure 2. Data Preparation Pipeline in RAG Systems

Data must be structured, encoded, and stored before the RAG pipeline can retrieve it. Each step affects what the system can access and use.
2.2 What Controls The Final Answer
At each step, small decisions shape what the model can produce:
- Retrieval determines which pieces are selected.
- Reranking re-scores retrieved results before they reach the model.
- Context determines what the model sees before responding.
Figure 3. Retrieval determines what the model sees.
From all available data, only a small subset is selected and passed into the model. The final response reflects this selection, not the full knowledge base.
In production RAG systems, reranking often has a significant impact on quality. It filters weaker matches and ensures the most relevant information moves forward.
When retrieval misses key details, the model fills the gaps from training patterns. Even strong models rely entirely on the information they receive. Outputs always reflect what the system provides.
3. Where RAG Systems Break
Failures occur at predictable points and rarely register as system errors. They appear as answers that sound reasonable but do not fully match the situation.
3.1 When Retrieval Fails
When the RAG system surfaces the wrong content, the model does not detect the gap or halt. It fills in missing context from its training distribution, producing outputs that are coherent but ungrounded.
The issue often comes from outdated data or weak matching between the query and stored content. Small drops in retrieval quality can significantly change the accuracy of what gets generated.
3.2 How Context Gets Lost
After retrieval, the system presents information in a form the model can use. Context begins to fail here. When retrieved content lacks coherence, the model struggles to interpret how pieces relate.
Even when relevant data is retrieved, models struggle to use all parts of the context effectively. This is known as the 'lost in the middle' effect (Liu et al., 2023). Relevant details become harder to access when buried in long inputs.
The response may include correct elements but still miss how they connect.
3.3 When Failures Start To Compound
As RAG systems move into production, data begins to drift across systems:
- Versioning: A policy update exists in one knowledge base but not another, creating disagreement about facts.
- Freshness: A product price changes in a catalog but remains outdated in supporting documentation.
- Consistency: A query pulling from an outdated snapshot provides a view of the world that no longer exists.
The model doesn't detect these mismatches. It generates responses from whatever version of the data is retrieved. Systems that support decisions or automation have limited tolerance for this kind of error.
Every failure here is a data supply chain problem. It starts where information lives and ends where the model needs it.
4. The 3 Levels Of RAG In Practice
The role of retrieval changes as systems scale. A basic RAG setup answers a single query. A more integrated system uses business data to resolve specific requests. In advanced applications, retrieval helps determine the next step in a workflow.
This progression follows three distinct patterns. The demands on data increase at each level.
4.1 Level 1: Basic RAG (Knowledge Assistants)
Basic RAG transforms knowledge base content into conversational answers. Accuracy depends on having complete, well-chunked data so retrieval can locate the right passage.
In preparing audio training data for a conversational AI system, we converted fragmented speech into a unified taxonomy. This taxonomy covered emotion and accent. Without that structural foundation, retrieval surfaces conflicting results for the same query.
Structure at this stage determines downstream reliability.
4.2 Level 2: Application RAG (Context-Aware Systems)
Application RAG connects retrieval to live operational data. Responses must reflect the current state of a record or transaction rather than a generalized answer.
Data must be current and tied to the correct user and context. While managing multi-team annotation pipelines, we saw how inconsistencies in batch reporting propagated directly into invoicing errors.
When the retrieval layer pulled from these misaligned records, it surfaced data that looked current but wasn't. The system responded accordingly.
4.3 Level 3: Agentic RAG (Decision Systems)
Agentic RAG supports tasks that require multiple steps. The system retrieves information, takes action, and updates its inputs as the task progresses. This creates a continuous reasoning loop.
At this stage, the core requirement is auditability. Each retrieval must be traceable so decisions can be corrected and reversed when needed.
In a multilingual rewriting project, we deployed agent-based workflows. Errors introduced early in the pipeline propagated across thousands of tasks when traceability was missing. Automation amplifies errors already present in the data.
What Makes RAG Reliable
RAG is often framed as a tool to reduce hallucinations. In practice, it changes what determines AI performance. Once a system relies on retrieval, its output quality depends on the data it can access.
Structure, freshness, and traceability shape how reliable that data is. This becomes critical as RAG takes on a larger role. At each level, weak retrieval carries more weight, moving from affecting outputs to shaping decisions.
For leaders, the priority must shift from ‘which model should we use?’ to ‘how healthy is the data flowing into our model?’ The answer sets the ceiling on what the system can deliver.
At Chemin, our work sits at the foundation of reliable retrieval. Every project we run is designed so that what gets retrieved is accurate, current, and traceable. This spans everything from audio annotation to agent-based workflows.
Connect with us to pressure-test your data flow before making scaling decisions based on it.
Discover more
Global vs Local: Testing GPT-4o-mini and SEA-LIONv3 on Bahasa Indonesia
We tested two Large Language Models (LLMs), GPT-4o-mini and SEA-LIONv3, on their handling of Indonesian-specific questions.
Chemin's Bilingual Dataset for Evaluating Reasoning Skills in STEM Subjects
Fresh out of the oven! Our team just released a bilingual multimodal dataset for evaluating reasoning skills in STEM Subjects.

Press Release: TDCX and SUPA tie-up to help companies address a key barrier in generative AI adoption
Collaboration provides companies with a one-stop-solution for their data labeling needs.